分享E3中GH_Function的应用方法和运算原
今天这里要为大家演示一下,E3如何控制调用多个gh文件,并组织它们有序运行,行程一个完成程序。这部分工作对我们研发来说尤为重要,相当于分步式开发,步骤的划分、先后的次序、运行的模式,这些都是我们所谓的程序运行框架,框架设计的好,程序跑的就好,就省,bug少。框架设计有问题,有可能程序的底子就没打好。
作为参数化设计师,我们接触这些框架设计的问题很少,虽然也我们也会基于模型的结构关系去编写有主次区别的生成构件,但与这里说的程序框架运行还相差很多。所以当我们跳出以往的参数化设计思维,开始独立思考程序的运算框架的时候,我们在智能化设计这条赛道上的开发能力就在不自觉的得到提升。E3的前身就是这样一个专门设计生成算法框架的工具,大家看到的诺亚住宅强排算法就是对应的成果。框架设计好了,才能解决大程序里运算分工、筛选、路由等宏观问题。
就拿住宅模块当个最简单的粒子来讲,它内部有很多的gh文件,有的负责解决用户客户端数据录入和分类的问题,有的负责处理用地红线重建debug的问题,有的负责初步强排预测方案,有的负责分类系统排楼,有的负责对反馈数据进行建筑单体调整,有的负责转移为人工可操作的模型数据,有的负责对整体结论进行二次优化……等等、每个运算步骤都是一个很大很大的运算模型、它们相互之间也不是单纯串联的关系,要做条件判断的筛选,要做运算结构的重组、要做运算路径的路由……有些模块可能不被选择、有些有跳过、有些要循环、有些要在后一个模块运算后遇到特定结果时返回到上一模块重新执行。这些情况显然是在我们只用gh时无法完成的,所以诺亚开发团队才会自研了GAAE,有将它升级到了今天的E3。
ok,前文少叙,我们正式开始
下载项目文件包
gh模板.zip (20.8 KB)
打开E3界面,录入账户后,进入这个面板,点击打开【本地项目】。

注意在E3中,每个研发项目是以文件夹的形式保存的,需要正确选择这个文件夹
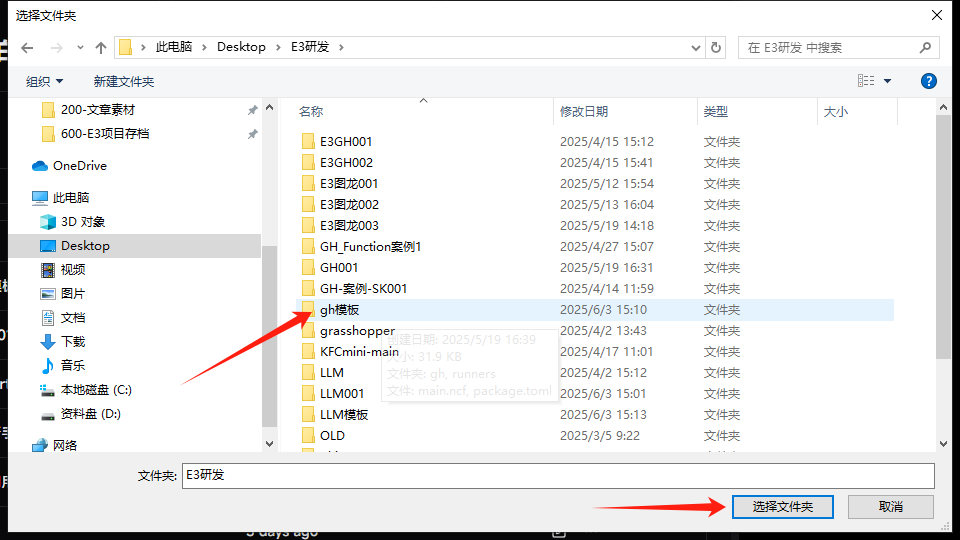
runners文件夹下的RunOnce和RunLoop是我们为大家准备好的两个gh运行模块,功能分别上运行一次(.gh文件)和循环运行(.gh文件)
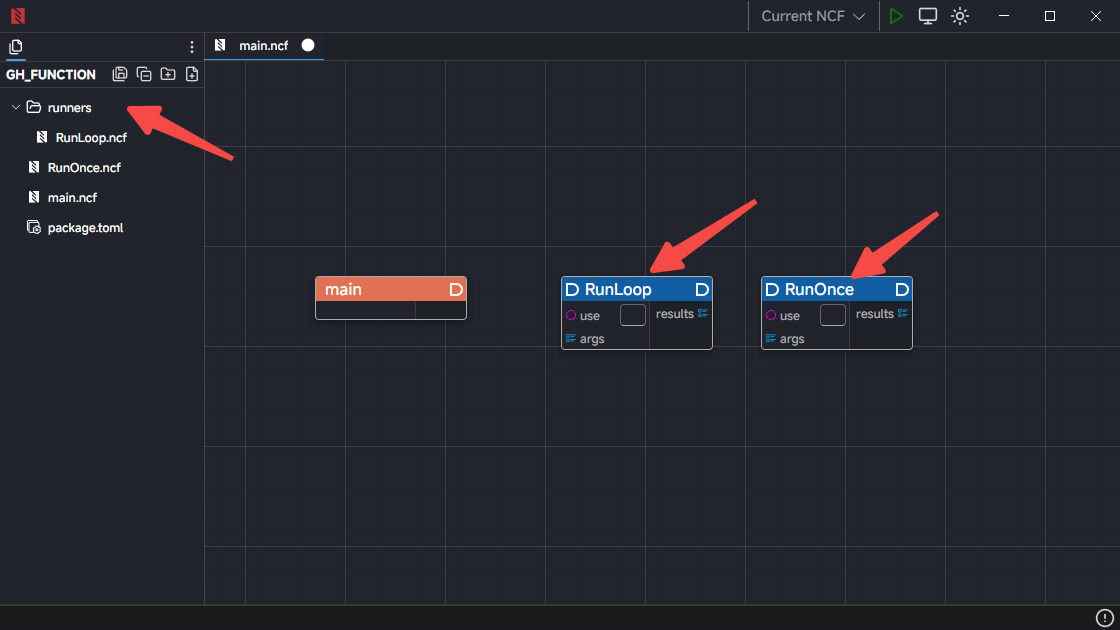
双击RunOnce功能模块,我们可以进入这个.ncf文件,看到其中内部的运算逻辑。箭头指的这个GH_Runner是核心模块,功能是执行.gh文件,输入端file链接文件地址,data往.gh文件内部输出数据,输出端惹results是将gh生成的数据传回到E3平台中。其他的功能模块作用是从编程的思维出发,在E3中创建一个叫Args的数据表单,用来传递和接收所有与.gh文件交互来往的数据。这个表单对于gh而言就像是一个全局变量一样。内部的每个数据都有一个key(名称),我们可以在.gh文件内部,通过input输入这个key,从而读到E3传递给gh的任意数据。(这部分未来会给大家单独开贴讲解,今天这里我们只要知道这个.ncf的功能和怎么用就好,平时调取运用的时候也无需打开它。)

进入main.ncf文件,新建三个.gh文件,手敲文件名就可以

串联三个RunOnce,然后在use里输入【DIR/s1.gh】意思是项目默认目录下+文件名,然后把每个模块的输出数据和输入数据收尾相接,results连给args,这样一个运行框架文件就配置好了。它代表了三个独立.gh文件在这个框架下依次运行,每个文件独立运行一次。注意上方的流程线决定了运行次序,下方的数据线决定了数据传递。

【注意这里有个圆点意思是.ncf文件尚未保存,需要Ctrl+S保存一下】

在项目管理面板,文件上右键可以打开项目文件夹,这里可以看到三个.gh文件(注意此时的文件还不是真实的.gh文件,只是叫这个名字,需要大家新建完.gh文件用另存为替换它们)
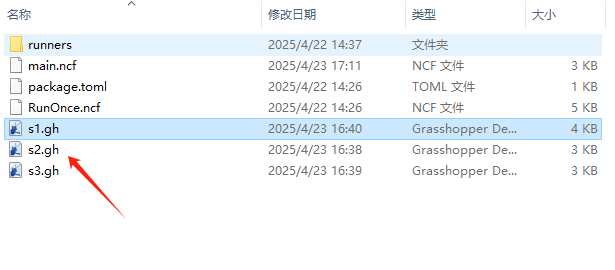
我这里为了演示文件数据的串联,新建了三个简单的加法,三个文件分别是这样的。每个文件的数据会通过output传递给E3,也会通过input传递回gh。
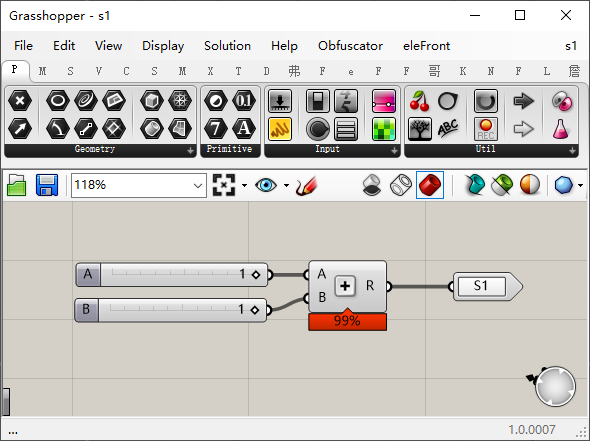

最后我们调出print模块,把最后一个RunOnce输出的数据打印出来看一下。结果是一个JSON数据,数据内容分别包含了S1、S2、S3 也就是所有gh文件output端口的数据输出情况。其中S1的数据是2;S2的数据是3;S3的数据是4。【注意如果到这里大家选用For Rhino版的话,大家也可以在第三个GH文件中,直接拿到这个结果。】

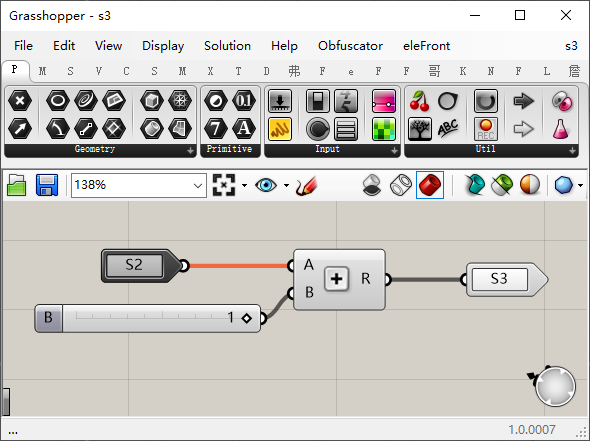
ok,下面我们来看看RunLoop即循环运行:让我们把第二个文件换成RunLoop,注意流程和数据连线,以及use端录入文件名目录。

然后我们把调用的s2.gh文件修改一下,加上红框里的部分,其中名称为【end】的output,是一个终止循环的开关,但这里输出的是false,意味着不终止循环,当这里出入true,意味着终止循环。所以我们在这里做了一个A大于B的比较,当S2的数值大于5时,会生成一个true给【end】用于终止循环,当S2的数值不大于5时,【end】拿到的值为false,循环会持续下去。

其次是输入端我们要多加一个名为【S2】的input,这里输出和输入都有【S2】这就是循环算法的特点。上一次循环中【S2】的输出数据会加入到下一循环中【S2】的输入数据里。同时我们面对【S1】和【S2】两个input要作路径筛选处理:当【S2】没有值时,读【S1】的值,当【S2】有值时,读【S2】的值。ok,这样循环就建立好了。

另有一个小知识点是,这个叫【i】的input,它会向gh里输出目前循环的次数是多少,是第几次运行循环。

我们在作一些编辑的过程中,会用到这个数据,比如我为了防止逻辑bug导致算法进入无限制循环的死局中,我就可以在这里作一个对【i】数据大小的限制,比如这个案例如果我想限制它最大不要运行超过10次,我就可以简单处理成如下这样:做一个大于10的判断,然后两个判断结果用“或门”链接,意思是这两个判断有一个是true,结果就为true。“与、或、非”门的概念在计算机逻辑编程里经常用到,大家可以网上自学一下,很简单。

【重要】最后记得一定要保存这个gh文件,因为e3此时调用的是s2.gh文件本身,如果不保存,它之前的就还是以前的保存文件。
成功运行后,我们看到最终数据输出的结果清单里,S2数值是6,是循环计算后的结果,并且在这个清单里我们看到了最后一轮循环结束时,Runloop的输出结果,i值是4,end为True,表示循环进行了四轮。

以上这些是E3 GH_Function模块如果分步式调用GH文件的方法。稍后为大家更新其他高级调控方法。